ImporterTool (или IT)
импортирует довольно неплохо простенькие html файлы. Именно за счет этого и были созданы все словари из под Lingvo. Что важно IT "видит" имена файлов с разного рода иероглифами (Windows использует UTF-16 для имен файлов - если у вас имена в Проводнике отображаются квадратиками, то советую поставить Directory Opus и настроить для показа файлов и папок шрифт типа Arial Unicode MS для полноценного отображения символов папок и файлов).
Особенностью импорта является то что разные версии ImporterTool имеют разный рендеринг html страниц. Во всяком случае версия 72 заметно отличается от 0.73. Например версия 0.72 создает файлы меньшего размера с более легкими таблицами. Если у вас нет желания что бы большие таблицы зависали в theWord то версия 0.73 вам категорически не подходит. Если импортируется какая-то художественная книга, то этого в принципе можно сильно не опасаться. Риск оправдан так как v.0.73 имеет заметные преимущества по части переноса стиля текста.
Кроме того версия 0.73 (в отличии от 0.72) создаёт поломанные Bookmarks. А исправлена эта проблема скорее всего будет в версии 0.75. Так как о проблеме стало известно уже после выхода v.074.
Версия 0.74 в принципе это та-же 0.73 с фиксом (касающимся заполнения таблиц в режиме сортировки файлов).
Заметное отличие версии 0.72 от 0.73 состоит в том что ранняя версия использует в процессе конвертации шрифт прописанный в первых строках языкового файла. А поздняя версия использует фиксированный шрифт (типа Tahoma) что делает v.73 малопригодной для импорта файлов диапазон символов которых не влазит в узкие границы этой Tahoma.
Что немаловажно Costas прислушивается к мнению пользователей в вопросах развития своего ПО. Так по моей просьбе он внедрил опцию переименования на лету импортируемых материалов.
Пример регулярного выражения для использования содержимого тега <Hn>...</Hn> в качестве заголовка карточки (где n - любое число от 0 до 9):
Использование этого выражения на практике привело к широкому появлению оглавлений сформированных за счет отступа:
 Проблема конверсии амперсанда (&)
Проблема конверсии амперсанда (&)
Большие неприятности для IT доставляет присутствие символа точки с запятой (;) в строке с амперсандом. Еще повезет если он (амперсанд) после конвертации в модуль будет стоять не в начале новой строки вместе с внезапно возникшим переносом. По этой причине амперсанд следует аккуратно заменять в файлах где это можно на его безопасный аналог :
& / U+FF06
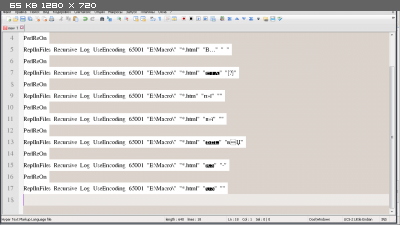
- Пример макроса для UltraEdit конвертирующего амперсанд на безопасный аналог:
Code: Select all
InsertMode
ColumnModeOff
HexOff
PerlReOn
ReplInFiles Recursive Log UseEncoding 65001 "E:\Macro\" "*.html" "&" "пј†"
 Внимание! Не удачный выбор последовательности или действий в ходе конвертации мнемоник и замены амперсанда на безопасный (после всех манипуляций по конвертации мнемоник) сделает очевидным для пользователя что в словаре встречаются некие коды требующие расшифровки. Ну по крайней мере это лучше чем пустое место на месте какого нибудь важного медицинского значка.
Внимание! Не удачный выбор последовательности или действий в ходе конвертации мнемоник и замены амперсанда на безопасный (после всех манипуляций по конвертации мнемоник) сделает очевидным для пользователя что в словаре встречаются некие коды требующие расшифровки. Ну по крайней мере это лучше чем пустое место на месте какого нибудь важного медицинского значка. 
Проблема конверсии мнемоник и числовых кодов Unicode.
Может возникнуть если вы импортируете html файлы напрямую с помощью Importer Tool. Версия 72 не все эквиваленты символов знает и соответственно не может конвертировать записи в символы Юникода.
Мало того и некоторые символы Unicoda неокрепший интеллект IT способен превращать в символы Кириллицы.
Пример тому смотрите на видео:
https://www.youtube.com/watch?v=FbrF8jaOvW0
На вопрос "каг-таг?" Костас кажется мысленно похвалил меня за изобретательность, но ответил что то вроде "IT не предназначена для конвертации html".
Так что в результате это даже и не ошибка а неудавшийся результат "научного" эксперимента.
Короче предварительная обработка числовых кодов Unicode и мнемоник при прямом импорте html крайне желательна.
В принципе эта проблема не катастрофичная - решается она преобразованием кодов с помощью пакетной фильтрации в TextPipe. После чего знак амперсанда & заменяется его безопасным аналогом U+FF06 Однако эти действия нужно производить на определенных стадиях процесса конвертации словарей из-за определенной вероятности появления в тексте нежелательных тегов.
- Внимание! Не следует бездумно заменять все в подряд в файлах html. Это может привести к тому что в коде html появятся символы которые интерпретатор html языка посчитает служебными символами html языка. Например могут появится скобки вида < >. И текст заключенный в эти скобки будет восприниматься как тег. Кроме того / (слеш) и вопросительный знак (?) применяются в языке разметки html в гиперссылках. Поэтому такие знаки надо заменять сразу на безопасные для html (а заодно и файловой системы) с помощью UltraEdit или TextPipe (бездумную замену в EmEditor как это описано ниже в данном конкретном случае не используйте).
Code: Select all
Символы мнемоник имеют вид ˜
Символы числовых кодов Unicode имеют вид ˜
Это проблема может быть решена как минимум двумя путями. С помощью программы EmEditor и с помощью поиска и замены в TextPipe. Если у вас один файл то его проще откорректировать в EmEditor. Если много то лучше использовать TextPipe.
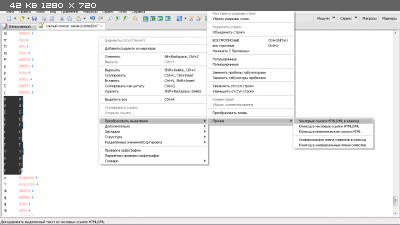
В EmEditor это делается через контекстное меню (правый клик мыши)
=> Преобразовать выделение => Прочие => Числовые имена символов XML|HTML в Unicode
В этом меню есть и другие варианты конвертации:
В TextPipe аналогичная проблема решается с помощью списка поиска и замен.
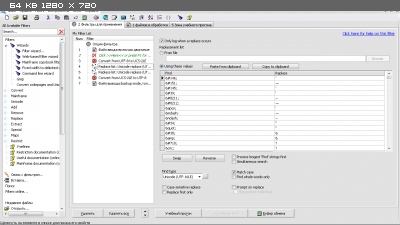
Пример фильтра для версии 9.52: